

AWS Data Architect Bootcamp - 43 Services 500 FAQs 20+ Tools
MP4 | Video: h264, 1280x720 | Audio: AAC, 44.1 KHz
Language: English | Size: 7.79 GB | Duration: 30h 26m
AWS Databases, EMR, SageMaker, IoT, Redshift, Glue, QuickSight, RDS, Aurora, DynamoDB, Kinesis, Rekognition & much more
What you'll learn
Confidently architect AWS solutions for Ingestion, Migration, Streaming, Storage, Big Data, Analytics, Machine Learning, Cognitive Solutions and more
Learn the use-cases, integration and cost of 40+ AWS Services to design cost-economic and efficient solutions for a variety of requirements
Answer detailed technical questions of your design and development teams regarding implementation and build
Practice hands-on labs on complex AWS services like IoT, EMR, SageMaker, Redshift, Glue, Comprehend and many more
Requirements
A computer with admin access, internet, and AWS Account to practice labs. Some labs may cost $$.
Basic working knowledge of AWS like AWS Console, S3, EC2, VPC and similar basic concepts.
Experience of working with at least one database, basic SQL, conceptual understanding of topics like replication, streaming, backups, key-value, index etc.
None of these are show-stoppers. Having this pre-requisite knowledge will make your journey through the course smoother with lesser questions
Description
Hi! Welcome to the AWS Data Architect Bootcamp course, the only course you need to learn everything about data architecture on AWS and play the role of an Enterprise Data Architect. This is the most-comprehensive AWS course related to AWS data architecture on the market. Here's why
This is the only online course taught by an Enterprise Cloud Architect, who leads large teams of junior architects in the real world, who has an industry experience of close to two decades in the IT industry, who is a published author, and leads technology architecture of XXX million dollar projects on cloud for multi-national clients. Data Architects draw a salary in the range of $150K - $250K on an average. This course trains you for that job! This is my 10th course on Udemy, 3rd on AWS topics (previous 2 are best-sellers).
Typical AWS classroom trainings on data architecture which contains a fraction of the topics covered in this course, costs $3000 - $5000. And this course teaches you 5 to 7 times more topics than AWS Training (40+ AWS Services) in the fraction of the cost.
Everything covered in this course is kept latest. Services which are in Beta and launched in Re-invent (last Nov) are already covered in the course . AWS innovates and adds features to their stack very fast, and I keep my course constantly updated with those changes. Think of this course as a Architecture Updates subscription.
Developers have questions, Architect's have questions, Clients have questions - All technical curious minds have questions. And this course also has 500+ questions and answers (FAQs) curated from AWS FAQs, to equip you with as many ready-to-use answers as you would need in your architect role.
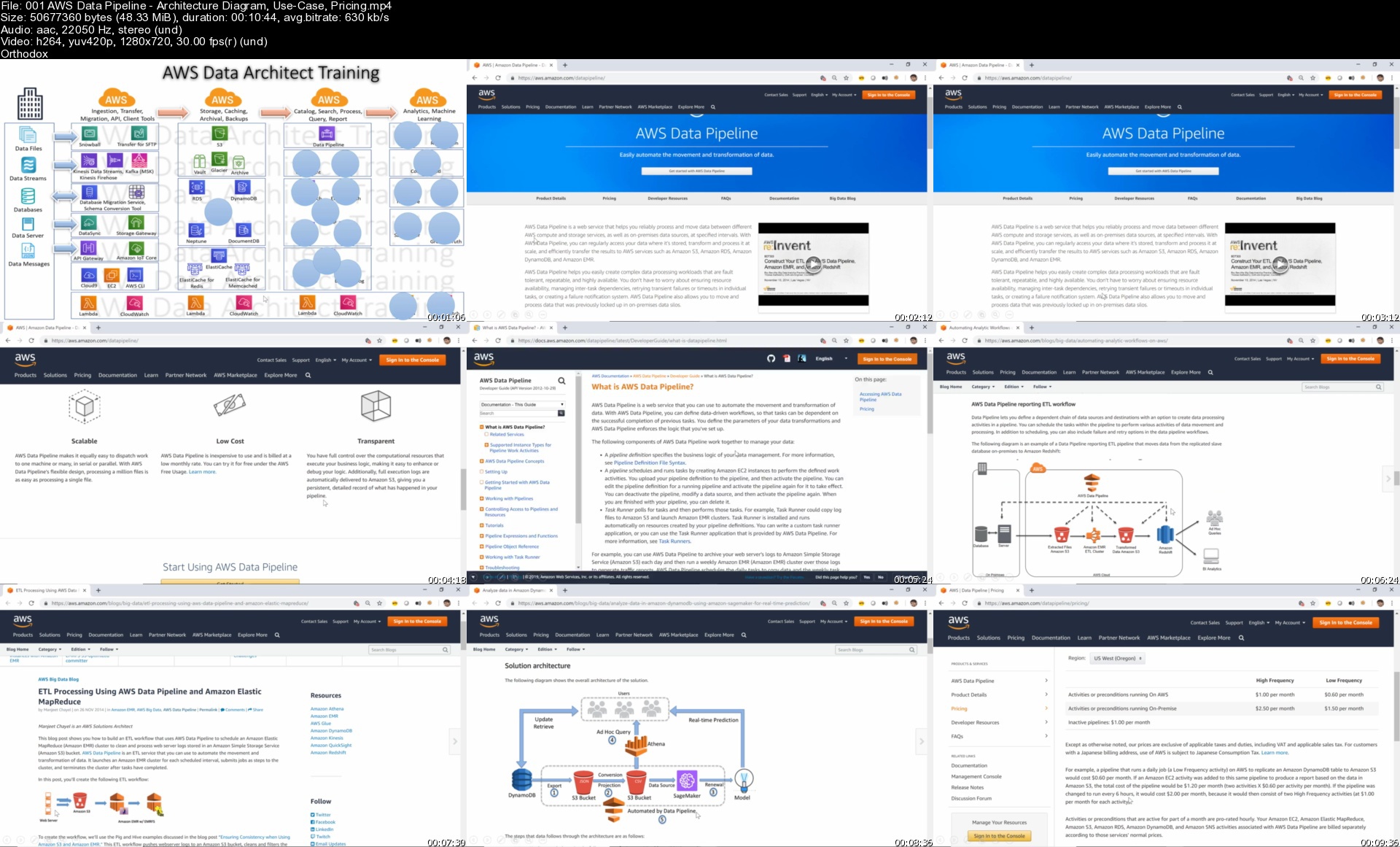
The entire course is formed of 40+ services. Every service is composed of the below listed sections, with their proportion in each section / service.
Architecture (12%) - Diagrams, Integration, Terminology
Use-Cases (6%) - Whether and When to use the AWS Service
Pricing (2%) - Cost estimation methods to assess overall solution cost
Labs (75%) - To-the-point labs for architectural understanding covering all major and important features
Frequently Asked Questions (5%) - Selected question from AWS FAQs explained concisely. (Total 500+)
Apart from AWS Services, we will use a number of client tools to operate on AWS Services, Databases and other technology stack. Here is a list of the tools that we would be using
1. EC2 2. Putty 3. Cloud9, 4. HeidiSQL 5. MySQL Workbench 6. Pgadmin 7. SSMS
8. Oracle SQL Developer 9. Aginity Workbench for Redshift 10. SQL Workbench / J
11. WinSCP 12. AWS CLI 13. FoxyProxy 14. Oracle Virtualbox 15. Linux Shell Commands
16. FastGlacier 17. Rstudio 18. Redis Client 19. Telnet 20. S3 Browser
21. Juypter Notebooks
Below is a detailed description of the curriculum as AWS Services we will be learning to understand how they fit in the overall cloud data architecture on AWS and address various use-cases. If you have any questions, please don't hesitate to contact me.
AWS Transfer for SFTP (Nov 2018 Release) - We will start our journey in this course with this service and learn how to ingest files in self-service manner using an sFTP server on AWS and sFTP tools on-premise to ingest file based data on AWS.
AWS Snowball - Large data volumes spanning hundreds of TBs are not ideal for ingestion via network. Using this service, we will learn how to ingest mega volume data using device based offline data transport mechanism to AWS cloud.
AWS Kinesis Data Firehose - One of the data ingestion mechanism is streaming. We will learn how to channel streamed data from Kinesis Data Streams to AWS Data Storage & Analytics Repositories like S3, Redshift, ElasticSearch and more using this service.
AWS Kinesis Data Streams - Clients can have streaming infrastructure or even devices (IoT) which may stream data continuously. Using this service we will learn how to collect streaming data and store it on AWS.
AWS Managed Streaming for Kafka (MSK) (Nov 2018 Release) - AWS recently added Kafka to their technology stack, which has lot of similarities with Kinesis. Learn comparative features as well as the method of standing up Kafka cluster on AWS to accept streaming data in AWS.
AWS Schema Conversion Tool - Database migration is a complex process and can be homogeneous (for ex. SQL Server on-premise to SQL Server on AWS) or heterogeneous ( for ex. MySQL to PostgreSQL). We will use this offline tool to learn about assessing migration complexities, generate migration assessment reports, and even perform schema migration.
AWS Database Migration Service (DMS) - Database Migration / Replication is a very common need for any federated data solution. We will use this service to learn how to migrate and/or replicate on-premise data from databases to AWS hosted relational databases on AWS RDS.
AWS Data Sync (Nov 2018 Release) - Continuous synchronization of data from on-premise to cloud hosted data repositories becomes a key requirement in environments where data is generated or changes very fast. We will use to service to learn how it can solve this requirement.
AWS Storage Gateway - This service has striking resemblance with AWS Data Sync, and is one of the alternatives for standing cached volumes and stored volumes on AWS to build a bridge between on-premise data storage and AWS. We will briefly learn similarities between AWS Data Sync and AWS Storage Gateway.
AWS ElastiCache ( Memcached ) - After covering most of the mechanisms of data ingestion, we will shift focus on caching data before moving on the databases. We will start learning about caching with Memcached flavor of this service which offers powerful caching capabilities for simpler data types.
AWS ElastiCache ( Redis ) - We will learn comparative difference between Memcached and Redis for caching, and learn how to use Redis flavor of caching which can build cache clusters and can host complex data types.
AWS S3 (Advanced) - AWS S3 is the basis of data storage and data lake in AWS. We will learn advanced tactics like locking data for legal compliance, cross-region global replication, data querying with S3 Select feature, Life-cycle management to move data to cold storage etc.
AWS Glacier - Data keep accumulating on cloud and can increase storage costs dramatically. Infrequently used data is suitable for cold storage, where this service comes into play. We will learning archival, archive retrieval and archive querying using this service.
AWS Relational Database Service (MariaDB) - We will be focusing heavily on AWS Service, which consists of 6 different types of databases. We will learn basic concepts of AWS RDS using MariaDB, stand-up an instance and query it with a client tool.
AWS Relational Database Service (SQL Server) - Data needs to be imported and exported between data-centers and cloud hosted database instances. We will learn such tactics for dealing with backups and restores across cloud using SQL Server database on RDS with a client tool.
AWS Relational Database Service (Oracle) - We will spend some time to learn how to stand up Oracle on AWS RDS, especially for Oracle professionals.
AWS Relational Database Service (MySQL) - After spending time on practicing basic concepts, with MySQL database on AWS RDS, we will start practicing advanced concepts for High-Availability and Performance, like Read Replicas and Performance Insights features.
AWS Relational Database Service (PostgreSQL) - There can be use-cases where there may be need to convert one database to another on cloud, for example convert PostgreSQL to MySQL. We will learn about some compatibility features where we can create a MySQL read replica from a PostgreSQL instance and make a read replica as an independent database.
AWS Relational Database Service (Aurora) - Aurora on AWS RDS is a native database service from AWS. It comes in two flavors - cluster hosted and serverless, which is suitable for different use-cases. Also the storage architecture of Aurora is shared by various other AWS services like AWS Neptune and DocumentDB. We will learn this service in-depth.
AWS Neptune - Relational databases is just one of the types of databases in the industry as well as on AWS. Graph is special use-case for very densely connected data where the value of relationships is much higher than normal. We will learn graph theory of RDF vs Property Graph, and learn how Neptune fits in this picture, stand-up a Neptune Server as well as client, and operate on it with query languages like Gremlin ( Tinkerpop ) and SPARQL.
AWS DocumentDB (Nov 2018 Release) - MongoDB is one of the industry leader in NoSQL Document Databases. AWS has recently introduced this new service which is a native implementation of AWS to provide an equivalent database with MongoDB compatibility. We will learn details of the same.
AWS DynamoDB - Key-value databases are important for housing voluminous data typically logs, tokens etc. We will learn document database implementation in depth with advanced features like streaming, caching, data expiration and more.
AWS API Gateway - REST APIs are today's standard mechanism of data ingestion. We will learn how to build data ingestion and access pipeline with APIs using this service with AWS DynamoDB.
AWS Lambda - Microservices are often tied with APIs, and are the cornerstone of any programmatic integration with AWS Services, typically AWS's Artificial Intelligence and Machine Learning Services. We will learn developing Lambda functions
AWS CloudWatch - System logging is at the center of all programmatic logic execution, and it ties very closely with microservices and metrics logging for a variety of AWS Services. We will learn how to access and log data from microservices in CloudWatch logs.
AWS Internet of Things (IoT) - Today IoT is one of the fastest growing areas, and from a data perspective, its one of the most valued source of data. The first challenge enterprises phase is the mechanism of ingesting data from devices and then processing it. With prime focus on ingestion, we will learn how to solution this using an end-to-end practical example which reads data from a device and sends text messages on your cell phone.
AWS Data Pipeline - With Data Lakes already overflowing with data, moving data within cloud repositories and from on-premises to AWS requires an orchestration engine which can move the data around with some processing. We will learn how to solve this use-case with this service.
Amazon Redshift and Redshift Spectrum - All stored data in relational or non-relational format needs to be analyzed and warehoused. We will learn how to cater the requirement for a peta-byte scale, massively parallel data warehouse using this service.
AWS ElasticSearch - ElasticSearch is one of the market leaders in search framework along with its alternative Apache Solr. AWS provides its own managed implementation of ElasticSearch, which can be used as one of the options to search data from different repositories. We will learn how to use this service for addressing search use-cases, and understand how tools like Logtash and Kibana fits in the overall solution.
AWS CloudSearch - Standing up an AWS ElasticSearch needs some ElasticSearch specific understanding. For use-cases which needs a more managed solution, AWS provides an alternative packaged solution for search based on Apache Solr. We will learn how to stand up this service and use if for standing up search solutions in an express manner.
AWS Elastic MapReduce (EMR) - After spending sufficient time on Ingestion, Migration, Storage, Databases, Search and Processing, now we will enter the world of Big Data Analytics where we will spend significant amount of time learning how to standup a Hadoop based cluster and process data with frameworks like Spark, Hive, Oozie, EMRFS, Tez, Jupyter Notebooks, EMR Notebooks, Dynamic Port Forwarding, RStudio on EMR, Read and Process data from S3 in EMR, Integrate Glue with Hive, Integrate DynamoDB with Hive and much more.
AWS Backup (Nov 2018 Release) - Creating backup routines of various data repositories is a Standard Operating Procedure of production environments. AWS made this job easier for support team with this brand new service. We will learn about the details of this service.
AWS Glue - AWS has centralized Data Cataloging and ETL for any and every data repository in AWS with this service. We will learn how to use features like crawlers, data catalog, serde (serialization de-serialization libraries), Extract-Transform-Load (ETL) jobs and many more features that addresses a variety of use-cases with this service.
AWS Athena - Serverless data lake is formed using four major services : S3, Glue, Redshift, Athena and QuickSight. This service is at the tail end of the process, and acts like a query engine for the data lake. We will learn how it serves that purpose and completes the picture.
AWS QuickSight - AWS filled the gap of a cloud-native reporting service in 2017 with the launch of this service. We will learn how it fits in the Serverless Data Lake picture and allows to create reports and dashboards.
AWS Rekognition - We will start our journey into the world of cognitive services powered by Artificial Intelligence with this service. Images and Video are vital source of data, and extracting information from these data sources and processing that data in a programmatic manner has various applications. We will learn how to perform this integration with Rekognition.
AWS Textract (Nov 2018 Release) - Optical Character Recognition is another vital source of data, for ex. we are very much used to scanning of bar codes, tax forms, ebooks etc. We will learn how to extract text from documents using this AI powered brand new service form AWS.
AWS Comprehend - Natural Language Processing (NLP) is a very big practice area of data analytics, typically performed using data science languages like R and Python. AWS makes the job of NLP easier by wrapping up a AI powered NLP service. We will learn the use of this service and understand how it complements services like Textract and Rekognition.
AWS Transcribe - One major source of data that we have not touched so far is Speech to Text. We will learn how to use this AP powered service to extract text from speech, and how it can be effectively used for a number of use-cases.
AWS Polly - We would have covered many use-cases of processing textual data from one form to another, but processing text to speech, which is the exact opposite function of Transcribe, we will learn to perform that with this AI powered service from AWS. We will also learn the use of Speech Synthesis Language to control the details of the speech that gets generated.
AWS SageMaker - After comfortably using AI powered service, which abstracts the complexity of machine learning models from end-users, we will now venture in the world of machine learning with this service. We will execute a machine learning model end-to-end and learn how to access data from S3, create a model, create notebooks for executing code to explore and process data, train - build - deploy machine learning model, tune hyper-parameters, and finally accessing it from a load balanced infrastructure using API endpoints.
AWS Personalize - Recommendation Engines requires building a reinforced deep learning neural network. Amazon has been in the business of recommending products to customers since decades. They have packages their method of recommendation as a product and launched it as a service, which is making a debut in the form of Personalize. We will perform an end-to-end exercise to understand how to use this service for generating recommendations.
AWS Lake Formation (Nov 2018 Release) - As forming data lakes is a tedious process, AWS has introduce a set of orchestration steps in the form of service to expedite the generation of Data Lakes. As this service is in early preview (Beta) and is subject to change, we will look at a preview of the GUI of this service before concluding the curriculum of this course.
If you are not sure whether this course is right for you, feel free to drop me a message and I will be happy to answer your question related to suitability of this course for you. Hope you will enroll in the course. I hope to see you soon in the class !
Who this course is for
Database professionals who are starting new on the AWS platform or are looking to learn a variety of AWS Services to widen their knowledge
Beginner or Experienced Data Architects who want to increase the breadth of their knowledge on AWS to start working at the next level
Technology Executives who want to quickly assess the suitability of any given AWS services for their use-cases
AWS Professionals who are preparing for Big Data Specialty Certification or preparing for a technical interview
Homepage
https://anonymz.com/?https://www.udemy.com/course/aws-data-architect-bootcamp-training/
https://k2s.cc/file/3d190c151553c/AWS_Data_Architect_Bootcamp_-_43_Services_500_FAQs_20__Tools.part1.rar https://k2s.cc/file/b1940197a0737/AWS_Data_Architect_Bootcamp_-_43_Services_500_FAQs_20__Tools.part2.rar https://k2s.cc/file/95f01fe18b065/AWS_Data_Architect_Bootcamp_-_43_Services_500_FAQs_20__Tools.part3.rar https://k2s.cc/file/aa84f217f0562/AWS_Data_Architect_Bootcamp_-_43_Services_500_FAQs_20__Tools.part4.rar
https://rapidgator.net/file/3e620f6032f23b28c9da73cde5763195/AWS_Data_Architect_Bootcamp_-_43_Services_500_FAQs_20__Tools.part1.rar.html https://rapidgator.net/file/41ad1dfe1d7b25a69c5fa8f31329bbb8/AWS_Data_Architect_Bootcamp_-_43_Services_500_FAQs_20__Tools.part2.rar.html https://rapidgator.net/file/a3c73954022e5f2a1ef2dc043b78628a/AWS_Data_Architect_Bootcamp_-_43_Services_500_FAQs_20__Tools.part3.rar.html https://rapidgator.net/file/ae72988d667cd5e35037d2ddfd49a344/AWS_Data_Architect_Bootcamp_-_43_Services_500_FAQs_20__Tools.part4.rar.html

